大规模模型在星际争霸中的技艺到底有多高?研究人员和汪军团队的最新发布

正是看到了这些挑战和机遇,**科学院自动化研究所的群体决策智能实验室与伦敦大学学院 (UCL) 的汪军教授合作,将最近兴起的 LLM Agent 技术应用于星际争霸 II 的 AI 研究。
团队通过 LLM 理解与分析能力来提高星际 AI 的长期战略规划与可解释性决策。为了提升 LLM 的长期战略规划能力,团队设计了 TextStarCraft II 环境和 Chain of Summarization (CoS) 方法。CoS 方法能够有效的提升 LLM 对复杂环境的理解能力,极大提高了 LLM 的战略规划和宏观策略能力。
该方法创造性的解决了 LLM 在长期战略规划和实时战略决策方面存在的不足,让 LLM agent 能够在星际争霸 II 这样的复杂 RTS 游戏中做出长期策略规划和实时策略调整,**进行合理且具有可解性的决策。
此外,团队邀请了 30 位大师和宗师级选手(包括了星际争霸 2 高校** TATP,ReWhite,Joliwaloves 等知名选手)对 GPT 等 LLM 在星际争霸 II 的相关知识进行测评。** LLM agent 涌现出了超越 AlphaStar 的危险预测和兵种转型能力,以及前期快攻,前期侦察,加速研发科技等类人策略。

TextStarCraft II:语言模型的新战场
面对星际争霸 II 这一巨大挑战,团队开发了 TextStarCraft II —— 一个全新的交互环境,它将星际争霸 II 转换成了一个文字游戏。这个环境基于 python-sc2 框架,将游戏中的状态信息和动作空间巧妙地映射到文本空间。在这里,宏观战略动作被转化为 LLM Agent 能够理解并执行的具体语义动作,大致包括生产单位,建造建筑和升级科技等。而微观操作则交由一套固定的规则式方法处理。
为了保证实验**的结果是得益于 LLM agent 的分析和决策能力,研究团队将宏观动作和微观动作都设置为最简单的情况,以避免过强的规则方法带来的干扰。得益于 TextStarCraft II,LLM agent 能够在这个全新的战场上与游戏内置的 Build-in AI 展开较量。同时借助 python-sc2,该方法能够适配游戏的**版本和地图,实现星际争霸 II AI 的灵活部署和**应用。
Chain of Summarization:突破思维的界限
在星际争霸 II 的战场上,进行有效决策意味着需要及时处理大量复杂的信息,进行合理的战略分析与长期规划,**制定宏观战略决策。这让团队面临着巨大的挑战。原有的 CoT (Chain of Thought) 及其改进方法,在 TextStarCraft II 环境中遭遇了三个主要问题:无法**理解复杂的游戏信息,难以分析战局的走向,以及不足以提出有用的策略建议。
为了应对这些挑战,我们的团队提出了一种创新的方法,称为「Chain of Summarization」。这种方法由两个核心组成部分组成:单帧总结和多帧总结。 在单帧总结中,我们侧重于将观测到的游戏信息进行压缩和提取,将其转化为简洁而富含语义的结构化数据,以便于LLM(Language Model)的理解和分析。 而多帧总结则受到计算机硬件缓存机制和强化学习中跳帧技术的启发。它通过同时处理多步观测信息,弥补了快节奏的游戏和LLM推理速度之间的差异,从而提高了LLM在复杂环境中的理解和决策能力。这种方法能够帮助LLM更好地适应游戏的节奏,并更准确地进行推理和决策。
 图1:Chain of Summarization 框架。
图1:Chain of Summarization 框架。
Complex Prompt System:构建智慧的桥梁
为了帮助 LLM 在实时战略决策中更加**,我们的团队设计了一个复杂的提示词系统。这个系统包括四个主要部分:游戏状态总结、状态分析、策略建议和**决策。通过这个系统,我们可以迅速总结当前的游戏状态,对状态进行深入分析,给出相应的策略建议,并**做出决策。这套系统的设计旨在提供有价值的信息,帮助 LLM 在实时战略中做出明智的选择。
通过这种方法,模型能够**理解游戏的当前状态,分析双方的策略,并给出具有战略深度的建议,**做出多步的合理决策。这不仅大大提高了LLM的实时决策和长期规划能力,还显著提高了决策的可解释性。在后续的实验中,LLM代理展现了前所未有的智能水平。
实验结果Chain of Summarization 对交互速度的提升
在验证 Chain of Summarization 方法的有效性方面,团队选择了 GPT-3.5-turbo-16k 作为 LLM。实验对比了应用和未应用该方法的两种情况。结果表明:Chain of Summarization 不仅将 LLM 与游戏端的交互速度提升到了之前的十倍,还显著增强了模型对游戏情境的理解及决策能力。

在这一系列实验中,团队选择了 GPT-3.5-turbo-16k 作为 LLM,并应用了 Chain of Summarization 方法。实验目的是测试 LLM Agent 扮演的神族玩家在与不同难度的虫族内置 AI 对抗中的表现。实验结果如下表所示:

类人策略的发现
在实验过程中,一个令人兴奋的发现是 LLM Agent 展现出了许多与人类玩家类似的策略。这些策略包括前期侦察、前期快攻、加速升级科技和兵种转型等。更为重要的是,团队观察到,在 Chain of Summarization 方法的帮助下,LLM Agent 能够通过观察、思考和决策来有效进行实时战略规划,实现了既具有可解释性又符合长期规划的决策。
1. 狂热者快攻
 2. 加速研发科技
2. 加速研发科技  3. 前期侦察
3. 前期侦察  4. 加速生产工人
4. 加速生产工人 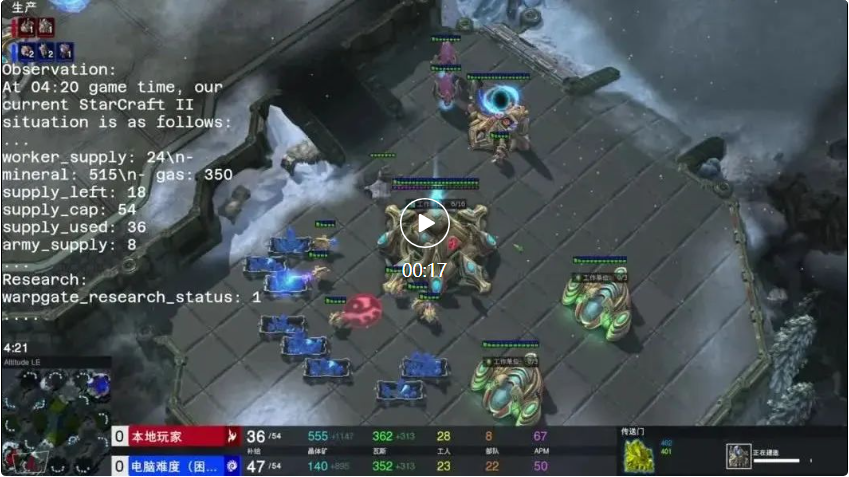 5. 防御与反击
5. 防御与反击 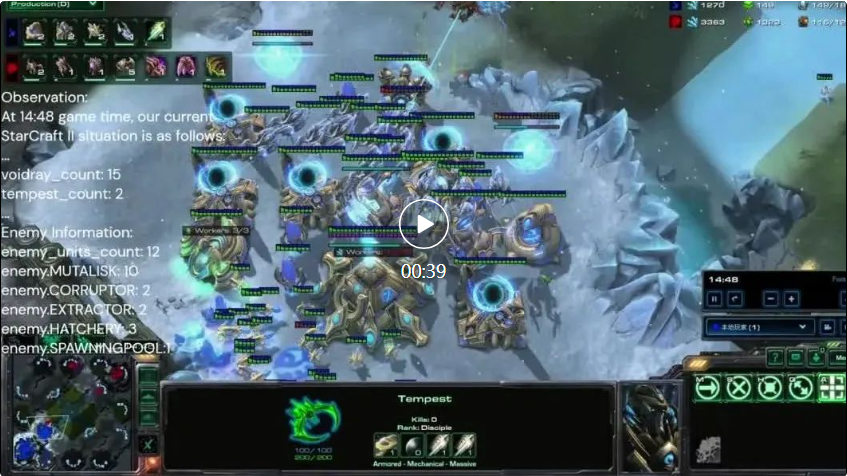 6. 侦测单位侦察
6. 侦测单位侦察  不同语言模型的表现
不同语言模型的表现为了进一步了解LLM在玩星际争霸II中表现出色的原因,研究团队提出了一个假设:这些LLM在预训练阶段可能已经学习到了与星际争霸II相关的知识。
为了验证这个假设,研究团队设计了一系列问题,涵盖了星际争霸 II 的基础知识、种族机制、典型战术、标准开局以及战术应对等方面。这些问题的答案由一组人类专家(包括大师和宗师级选手)和GPT-4进行双盲评分,以评估不同模型对星际争霸 II 知识的掌握程度。
根据实验结果显示的图表,我们可以观察到一个有趣的现象:这些模型在不同程度上对星际争霸 II 的相关知识有**的掌握,其中 GPT-4 在理解和回答这些问题方面表现尤为出色。这个发现不仅验证了我们团队的假设,也为我们对于 LLM agent 在复杂现实场景中的应用提供了新的视角。

在 AI 领域,即使是像 AlphaStar 这样能击败人类职业选手的强大 AI,有时也会做出一些难以理解或解释的决策。相比之下,尽管 LLM Agent 可能无法达到 AlphaStar 那样精细的微操作水平,但其强大的逻辑思考能力使其能够分析乃至预测游戏走向,并提供更合理的决策。这一能力主要体现在两个方面:
1. 预测危险与建立防御:如左图所示,AlphaStar(蓝色虫族)在对抗大师级玩家(红色神族)时,未能及时建造防空建筑来应对对手的骚扰,导致了重大损失。而在右图中,LLM Agent(绿色神族)通过预判对手(红色虫族)的攻势,及时建造了护盾电池,成功进行了防御。
 2. 战场形势下的兵种转型:在另一场比赛中,AlphaStar(蓝色虫族)面对大师级玩家(红色人族)的机械化部队时,并未做出有效的兵种转型,导致资源和人口的浪费(见左图)。相对而言,LLM Agent(红色神族)在面对敌方(蓝色虫族)时,不仅迅速生产出克制对手的部队,还进一步研发了相关科技,实现了合理的部队转型和策略拓展(见右图)。
2. 战场形势下的兵种转型:在另一场比赛中,AlphaStar(蓝色虫族)面对大师级玩家(红色人族)的机械化部队时,并未做出有效的兵种转型,导致资源和人口的浪费(见左图)。相对而言,LLM Agent(红色神族)在面对敌方(蓝色虫族)时,不仅迅速生产出克制对手的部队,还进一步研发了相关科技,实现了合理的部队转型和策略拓展(见右图)。 
LLM(Language Model)代理是一种基于人工智能技术的语言模型代理,它具有广阔的潜力和应用前景。未来,LLM代理有望在许多领域发挥重要作用。 首先,LLM代理可以应用于自然语言处理领域。它可以用于机器翻译、语音识别、情感分析等任务,
展望未来,团队期待 TextStarCraft II 环境能够成为评估 LLM 及 LLM Agent 能力的重要标准。此外,团队认为未来将 LLM 与强化学习相结合,会产生更**的策略和更佳的可解释性,能够解决星际争霸 II 以及更复杂的决策场景。这种方法不**潜力超越 AlphaStar,还可能解决更加复杂和多变的决策问题,从而为 AI 在现实社会中的应用开辟新的道路。